

Een functionele aanpak in de ontwikkeling van een nieuw woordenboek VGT-NL
Caro Brosens, Sam Verstraete, Thijs Vandamme, Hannes De Durpel, Margot Janssens, Lisa Rombouts
Introductie
In 2019 lanceerde het VGTC het (ver)nieuw(d)e woordenboek Vlaamse Gebarentaal (VGT) – Nederlands (NL). In deze tekst wordt het verloop van dit vernieuwingsprocess uitgelegd. Eerst wordt er kort geschetst wat voorafging aan het nieuwe woordenboek. Daarna wordt er dieper ingegaan op drie belangrijke fases in de ontwikkeling van het nieuwe woordenboek, namelijk: de noden en wensen van de gebruikers onderzoeken, de data opschonen, en bepaalde elementen van het woordenboek vernieuwen of verbeteren. Tot slot worden de toekomstplannen voor het woordenboek overlopen.
Wat voorafging
Vanaf de jaren ‘90 kwam het onderzoek naar VGT op gang. Van daaruit ontstond de vraag naar een tweetalig woordenboek. Vanaf 1999 liepen er verschillende kleinschalige lexicografische projecten over heel Vlaanderen. Dit leidde tot de lancering van het eerste woordenboek VGT – NL, gebaren.ugent.be, in 2004.
In dat woordenboek werden gebaren op verschillende manieren weergegeven: een videoclip, een Nederlandse vertaling en SignWriting. Dat laatste maakte het mogelijk om op te zoeken in twee richtingen: van Vlaamse Gebarentaal naar Nederlands (op basis van de handvorm, locatie of beweging via SignWriting) en van Nederlands naar Vlaamse Gebarentaal (op trefwoord zoeken of scrollen in de alfabetische lijst met Nederlandse trefwoorden) (Vermeerbergen & Van Herreweghe, 2018).

Afbeelding 1: Een screenshot van de homepagina van gebaren.ugent.be
Het VGTC was echter al een tijd aan het ijveren voor een grondige herziening van de gebruikersomgeving. 15 jaar na de lancering van het eerste woordenboek leken de verwachtingen van de gebruikers immers niet meer ingelost. Bovendien was de technologie sinds 2004 sterk vooruitgegaan, waardoor de mogelijkheden voor een toegankelijk online referentiewerk flink werden uitgebreid (McKee & McKee, 2013). Een gemengd gebruikersonderzoek, waar later nog dieper op wordt ingegaan, bevestigde dit vermoeden.
Eind 2018 kreeg het VGTC een eenmalige projectsubsidie om het woordenboek grondig te vernieuwen. Bij deze vernieuwing hoorde een praktische benadering: vanuit het beschikbare onderzoek de taal beschrijven zoals die in de gemeenschap voorkomt, en altijd rekening houden met de verwachtingen, noden en vaardigheden van de gebruikers (Atkins & Rundell, 2008).
Het nieuwe woordenboek ontwikkelen
Gebruikersonderzoek
Het doel was om meer te doen dan enkel onderzoeksresultaten op een website plaatsen. Het woordenboek moest een praktisch, toegankelijk en gebruiksvriendelijk referentiewerk worden dat tegemoetkomt aan de noden, verwachtingen en vaardigheden van de gebruikers. Om een beter beeld te krijgen van wie deze gebruikers waren, werden er verschillende bronnen geraadpleegd: het gebruikersonderzoek van Joni Oyserman (2013), de kwantitatieve data van Google Analytics, en gebruikersprofielen die door het VGTC werden opgesteld.
In de studie van Joni Oyserman werden dove en horende VGT-lesgevers, tolken, VGT- studenten, dove en horende ouders van een doof kind en familieleden van een dove persoon bevraagd rond hun gebruikspatronen van het woordenboek. Een van de resultaten uit het onderzoek was dat gebruikers graag zowel van VGT naar NL als van NL naar VGT zoeken. Ook de wens om thematisch te zoeken werd geuit. Tijdens de ontwikkeling van het nieuwe woordenboek VGT werd hiermee rekening gehouden.
Daarnaast werden ook de data van Google Analytics geanalyseerd. Deze tool registreert welke gebaren het meest bekeken worden, hoe lang bezoekers een bepaalde pagina bekijken en hoe er wordt gezocht. Hieruit bleek dat slechts een klein percentage van alle zoekopdrachten van VGT naar NL was. Dit lijkt echter lijnrecht tegenover het onderzoeksresultaat hierboven te staan. Een mogelijke verklaring hiervoor is dat de SignWriting-symbolen niet toegankelijk genoeg zijn voor de gemiddelde gebruiker. Een ander vermoeden is dat de zoekfunctie te veel resultaten weergeeft om vlot bij de gewenste informatie te komen.
Bovendien was het aantal nieuwe bezoekers aanzienlijk hoger dan het aantal terugkerende bezoekers. Dat zou erop kunnen wijzen dat de inhoud van het woordenboek ontoereikend was. Daarnaast viel het op dat gebruikers het woordenboek in de helft van de gevallen via een mobiel toestel raadpleegden, hoewel de webapplicatie op dat moment niet-responsief was en bijgevolg minder toegankelijk op smartphones en tablets. Op die manier werd duidelijk dat de vraag naar een responsieve website, die zich automatisch aan de grootte van het scherm aanpast, groot was.
In samenwerking met AE, het softwarebedrijf waar het VGTC mee heeft samengewerkt, werden er fictieve gebruikersprofielen gemaakt om de hypotheses uit bovenstaande studies te testen. Tijdens de ontwikkeling werd ook elke versie van de applicatie getest door een kleine groep gebruikers. In april 2019 werd er een testmoment georganiseerd waarbij acht vrijwillige informanten (twee dove senioren, twee dove jongeren, twee tolken, twee horende tolkstudenten) gedurende een uur verscheidene zoekopdrachten moesten uitvoeren. Hun bevindingen werden meegenomen in de verdere ontwikkeling van de gebruikersomgeving van het woordenboek.
Data opschonen
Sinds 2017 gebruikt het VGTC Signbank, een elektronische databank gericht op het verzamelen van gebarenschat. Aangezien gebarentalen visuele talen zijn, is het belangrijk om een databank te gebruiken waarin je gemakkelijk met videomateriaal kunt werken. Bovendien kan je in Signbank nog veel andere relevante informatie toevoegen.
Naast alle data uit het vorige woordenboek werden ook de resultaten van lexicografische onderzoeksprojecten van het VGTC uit 2004 en later aan Signbank toegevoegd. Ook de gebaren op VGT drop, een community sourcing website opgestart in 2016, werden in Signbank ingevoegd.
Daarnaast kan het VGTC nu eenvoudiger gebaren verzamelen. Medewerkers kunnen bijvoorbeeld gemakkelijker discussies op sociale media en dergelijke opvolgen. Al moet hierbij wel worden opgemerkt dat dit een tijdrovende opdracht is, aangezien het opvolgen van zo’n discussies veel manuele arbeid vraagt. Verder wordt er bij elk gebaar dat wordt toegevoegd ook de bron vermeld, zodat gerichter onderzoek mogelijk is. In elk geval is Signbank de centrale kern geworden waarin alle lexicografische data van het VGTC worden opgeslagen. Deze data worden nu gebruikt om het woordenboek te “voeden”.
Het samenbrengen van al deze ruwe data zorgde echter voor inconsistenties en kleine foutjes, zoals dubbele gebaren met een (licht) andere glos, inconsistente of verwarrende
glossen, ontbrekende informatie, typfouten,… Hierdoor moesten de data manueel worden nagekeken en aangevuld. Daarnaast werden in 2018 en 2019 een deel van de oude video-opnames in Signbank vernieuwd. Dit proces wordt overigens verdergezet tot alle video’s vernieuwd zijn.
Omdat SignWriting niet erg toegankelijk en efficiënt bleek te zijn, werd er beslist om het niet langer op te nemen in het nieuwe woordenboek. Voor de vernieuwde zoekfunctie werden er voor elk gebaar twee parameters beschreven in Signbank, namelijk handvorm en locatie. Dit was gebaseerd op het doctoraatsonderzoek van Eline Demey (2005). Indien beschikbaar, werd de SignWriting van het vorige woordenboek wel als vertrekpunt gebruikt om de fonologie van de gebaren aan te vullen. De rest werd handmatig gedaan.
Om thematische zoekopdrachten mogelijk te maken, kregen gebaren tijdens deze fase ook een of meer semantische categorieën toegewezen (bv. natuur, wet, sport, gezondheid, familie,…). De onderzoeksaanpak van het vorige woordenboek ligt aan de basis van de semantische categorieën in dit woordenboek. Voor meer informatie, zie Vermeerbergen en Van Herreweghe (2018). De originele lijst van semantische categorieën werd gereduceerd en herwerkt. Er waren daarbij drie mogelijkheden: 1) de categorie werd behouden (en misschien hernoemd), 2) de categorie zou samenvloeien met een andere categorie, of 3) de categorie zou niet meer bestaan.
Om te bepalen welke gebaren uit Signbank worden opgenomen in het woordenboek, komt drie tot vier keer per jaar een groep van zorgvuldig geselecteerde dove near-native signers (een van elke van de vijf Vlaamse provincies) samen. Hierbij is er minstens één medewerker van het VGTC aanwezig om de discussie te leiden. Op zo’n bijeenkomst worden gebaren uit Signbank besproken die het label “expertgroep” dragen. Door praktische zaken zoals iedereen fysiek samenbrengen en het manueel verwerken van data brengt de kwalitatieve kant van deze aanpak ook mee dat dit een tijdrovende en inefficiënte manier van werken is. De data zouden daarom bij voorkeur aangevuld moeten worden met kwantitatieve data vanuit het corpus VGT. Daarom werkt het VGTC sinds 2019 aan een verbinding tussen Signbank en ELAN, het programma waarmee het corpus wordt geannoteerd. Op die manier hopen we de lexicografische basis van Signbank te kunnen versterken. Tegelijkertijd wordt er naar alternatieve manieren gezocht om het bestaan en de verspreiding van gebaren te verifiëren.
Vernieuwingen
Allereerst zijn de zoekfuncties uitgebreid, waardoor gebruikers nu op verschillende manieren tot een bepaald gebaar kunnen komen. Er kan onder andere op handvorm en locatie van een gebaar worden gezocht. Anders dan in de vorige versie van het woordenboek wordt die zoekfunctie niet langer mogelijk gemaakt door SignWriting, maar door afbeeldingen van handvormen en locaties op het lichaam. Via toegankelijke informatie-iconen wordt op een begrijpelijke manier uitgelegd wat handvormen en locaties precies zijn, zowel in VGT als in het Nederlands. Verder kan er ook vanuit het Nederlands naar VGT worden gezocht. In de zoekbalk kan er namelijk een Nederlands woord worden getypt, waarna alle mogelijke VGT-equivalenten voor dat ene woord verschijnen. Daarnaast is het ook mogelijk om op regionale variant of semantische categorie te zoeken. Om een bepaalde zoekopdracht sneller te vinden, kunnen verschillende zoekfilters ook met elkaar worden gecombineerd.
Ten tweede is het nu ook mogelijk om de detailpagina van een gebaar te raadplegen. Zo komen gebruikers in één klik meer te weten over de fonologie en semantische categorie van een gebaar. Dankzij kruisverwijzingen worden gebruikers gemakkelijk doorverwezen naar gebaren die fonologisch verwant zijn of die dezelfde betekenis hebben, maar in een andere regio worden gebruikt.
Ten derde kunnen er in het nieuwe woordenboek ook meerdere Nederlandse vertalingen aan één enkel gebaar worden toegekend. Zo kunnen gebruikers in één oogopslag verschillende synoniemen bij hun zoekopdracht zien verschijnen.
Naast deze inhoudelijke wijzigingen is de website ook structureel aangepast. Wanneer je de website nu op een smartphone of een tablet raadpleegt, zal het beeld zich namelijk automatisch aanpassen aan de grootte van het scherm. Zo blijft het woordenboek altijd even toegankelijk als op een computer. Verder is de gebruikersomgeving ook visueler georganiseerd. Door de video’s een prominentere plaats te geven, ligt de focus nu meer op de gebaren en niet meer op de Nederlandse vertaling.
Tot slot kunnen gebruikers nu ook feedback geven op de werking van het nieuwe woordenboek. Die feedback kan gaan van technische problemen tot meer inhoudelijke opmerkingen. Als reactie daarop krijgt het gebaar een tag in Signbank en volgt er verder taalkundig onderzoek. Daarnaast krijgt het VGTC, als beheerder van het nieuwe woordenboek, ook telkens een melding wanneer gebruikers een gebaar zoeken, maar daar geen resultaten voor vinden. Op die manier wordt duidelijk welke gebaren de gebruikers in het woordenboek missen.
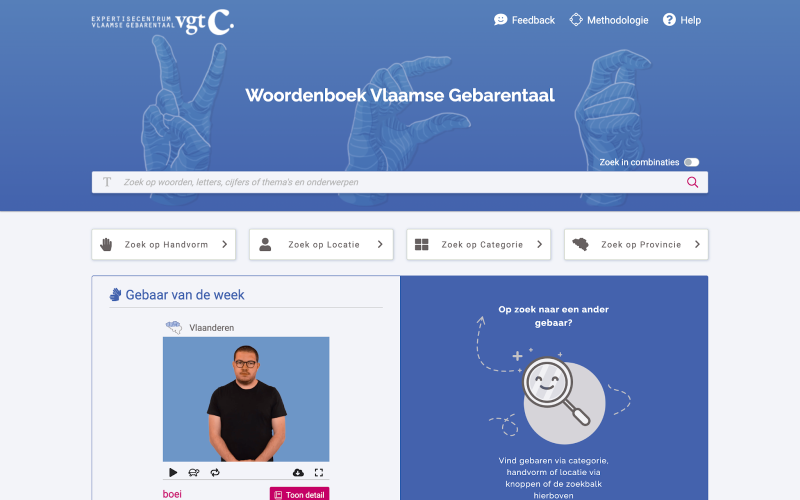
Afbeelding 2: Een screenshot van de homepagina van het (ver)nieuw(d)e woordenboek
Toekomstplannen
Het maken van een gebruiksvriendelijk tweetalig woordenboek is een proces dat nooit volledig klaar is. Dit project betekent een grote stap vooruit voor het woordenboek VGT-NL, maar het is zeker nog niet het eindpunt.
Net zoals bij het vorige woordenboek is er geen garantie dat alle gebaren die in Vlaanderen worden gebruikt in het woordenboek staan. Een gebaar dat (nog) niet in het woordenboek staat, is dus niet per definitie fout of minder juist dan gebaren die al wel opgenomen zijn.
Het VGTC tracht voortdurend zowel het gebruiksgemak als de inhoud van het woordenboek te verbeteren. Naast het uitbreiden van het aantal gebaren in het woordenboek, zijn andere toekomstige doelen o.a. het toevoegen van definities en voorbeeldzinnen (in VGT en in mindere mate Nederlands), alsook informatie over het gebruik en de oorsprong van de gebaren.
Zoals Atkins en Rundell (2008) stellen, moet er bij de inhoud en vormgeving van elk aspect van een woordenboek centraal staan wie de gebruikers zijn en waarvoor zij het woordenboek gebruiken. Ook het VGTC is er sterk van overtuigd dat meer diepgaand gebruikersonderzoek, ook tijdens en na de ontwikkeling van een gebarentaalwoordenboek, van cruciaal belang is om een duurzaam naslagwerk op te bouwen. Alleen zo kan er steeds aan de wensen van de gebruikers worden voldaan en zullen zij met plezier het woordenboek blijven gebruiken.
Bronnen
Atkins, B.T. & Rundell, M. (2008). The Oxford Guide to a Practical Lexicography. New York: Oxford University Press Inc.
Demey, E. (2005). Fonologie van de Vlaamse Gebarentaal: distinctiviteit en iconiciteit. Universiteit Gent. Faculteit Letteren en Wijsbegeerte, Gent.
McKee, R., & Mckee, D. (2013). Making an Online Dictionary of New Zealand Sign Language. Lexikos. 23. 10.5788/23-1-1227.
Oyserman, J. (2013). Enquête resultaten gebruikersonderzoek online woordenboek Vlaamse Gebarentaal. Vlaams GebarentaalCentrum vzw.
Vermeerbergen, M. & Van Herreweghe, M. (2018). Looking Back While Moving Forward: The Impact of Societal and Technological Developments on Flemish Sign Language Lexicographic Practices. International Journal of Lexicography, 31(2), 167–195.

